Single Node Hadoop Tutorial
Hands-on lab on Hadoop Map-Reduce
Objectives
- Run a single-node Hadoop instance
- Perform a word count using Hadoop Map Reduce.
Set up Single-Node Hadoop
The steps outlined in this lab use the single-node Hadoop Version 3.2.3. Hadoop is most useful when deployed in a fully distributed mode on a large cluster of networked servers sharing a large volume of data. However, for basic understanding, we will configure Hadoop on a single node.
In this lab, we will run the WordCount example with an input text and see how the content of the input file is processed by WordCount.
- Start a new terminal

- Download hadoop-3.2.3.tar.gz to your theia environment by running the following command.
curl https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz --output hadoop-3.2.3.tar.gz
- Extract the tar file in the currently directory.
tar -xvf hadoop-3.2.3.tar.gz
- Navigate to the hadoop-3.2.3 directory.
cd hadoop-3.2.3
- Check the hadoop command to see if it is setup. This will display the usage documentation for the hadoop script.
bin/hadoop
- Run the following command to download data.txt to your current directory.
curl https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-BD0225EN-SkillsNetwork/labs/data/data.txt --output data.txt
- Run the Map reduce application for wordcount on data.txt and store the output in /user/root/output
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount data.txt outputThis may take some time.
- Once the word count runs successfully, you can run the following command to see the output file it has generated.
ls output
You should see part-r-00000 with _SUCCESS indicating that the wordcount has been done.
While it is still processing, you may only see '_temporary' listed in the output directory. Wait for a couple of minutes and run the command again till you see output as shown above.
- Run the following command to see the word count output.
cat output/part-r-00000

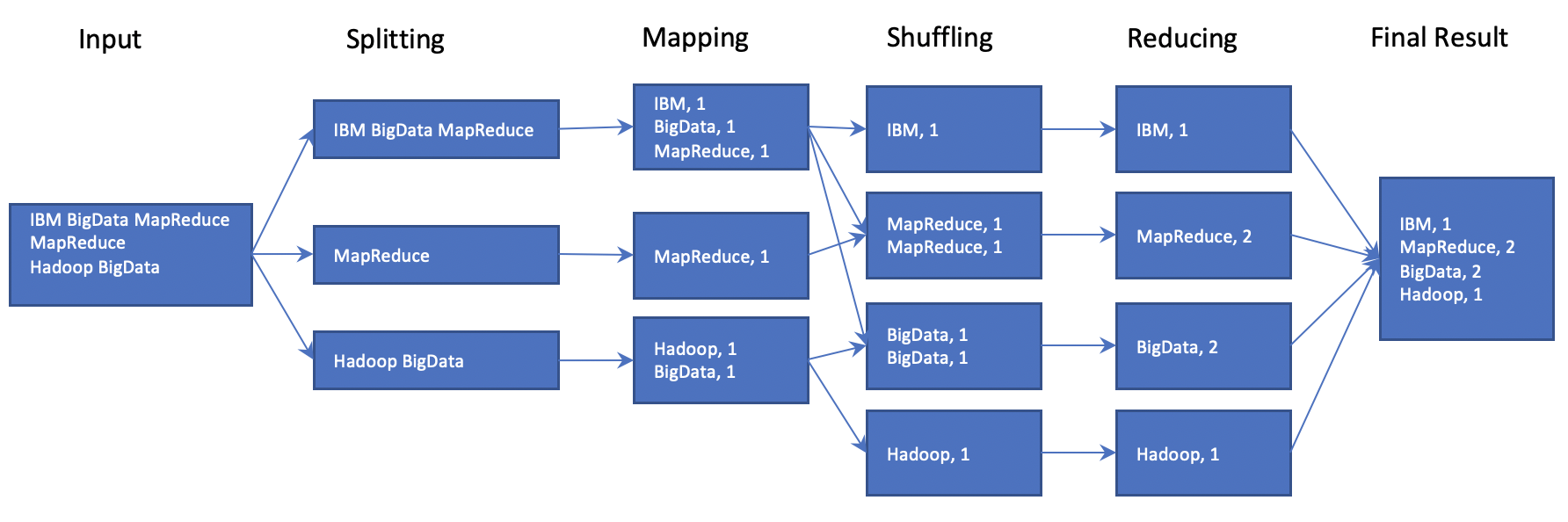
The image below shows how the MapReduce wordcount happens.
Practice Lab
- Do a word count on a file with the following content.
India Italy Venice Italy Pizza India Pizza Pasta Gelato
Do a word count on a file with very large content, try to find any text file that is in GBs and observe it.
Comments
Post a Comment